
IT之家 12 月 28 日音尘加拿大pc28官网走势神测,谷歌 DeepMind 团队最新推出了“可微缓存增强”(Differentiable Cache Augmentation)的新门径,在不清醒迥殊增多策画职守的情况下,不错显赫进步诳言语模子的推感性能。
技俩布景IT之家注:在话语处理、数学和推理界限,大型话语模子(LLMs)是措置复杂问题不能或缺的一部分。
策画技巧的增强侧重于使 LLMs 粗略更灵验地处理数据,生成更准确且与高下文估量的反映,跟着这些模子变得复杂,贪图东谈主员致力于确立在固定策画预算内动手而不就义性能的门径。
小沈平时不穿冲锋衣,但自从10月初,小沈追的男明星成毅代言了国产冲锋衣品牌伯希和之后,一切都变了。一个月的时间,她的衣橱里已经躺着三件伯希和的冲锋衣。
优化 LLMs 的一大挑战是它们无法灵验地跨多个任务进行推理或奉行超出预磨真金不怕火架构的策画。
现时提高模子性能的门径波及在职务处理时刻生成中间门径,但代价是增多延长和策画服从低下。这种搁置遏抑了他们奉行复杂推理任务的才略,相等是那些需要更长的依赖关联或更高地预计准确性的任务。
技俩先容“可微缓存增强”(Differentiable Cache Augmentation)摄取一个经过磨真金不怕火的协处理器,通过潜在镶嵌来增强 LLM 的键值(kv)缓存,丰富模子的里面记念,重要在于保握基础 LLM 冻结,同期磨真金不怕火异步动手的协处理器。
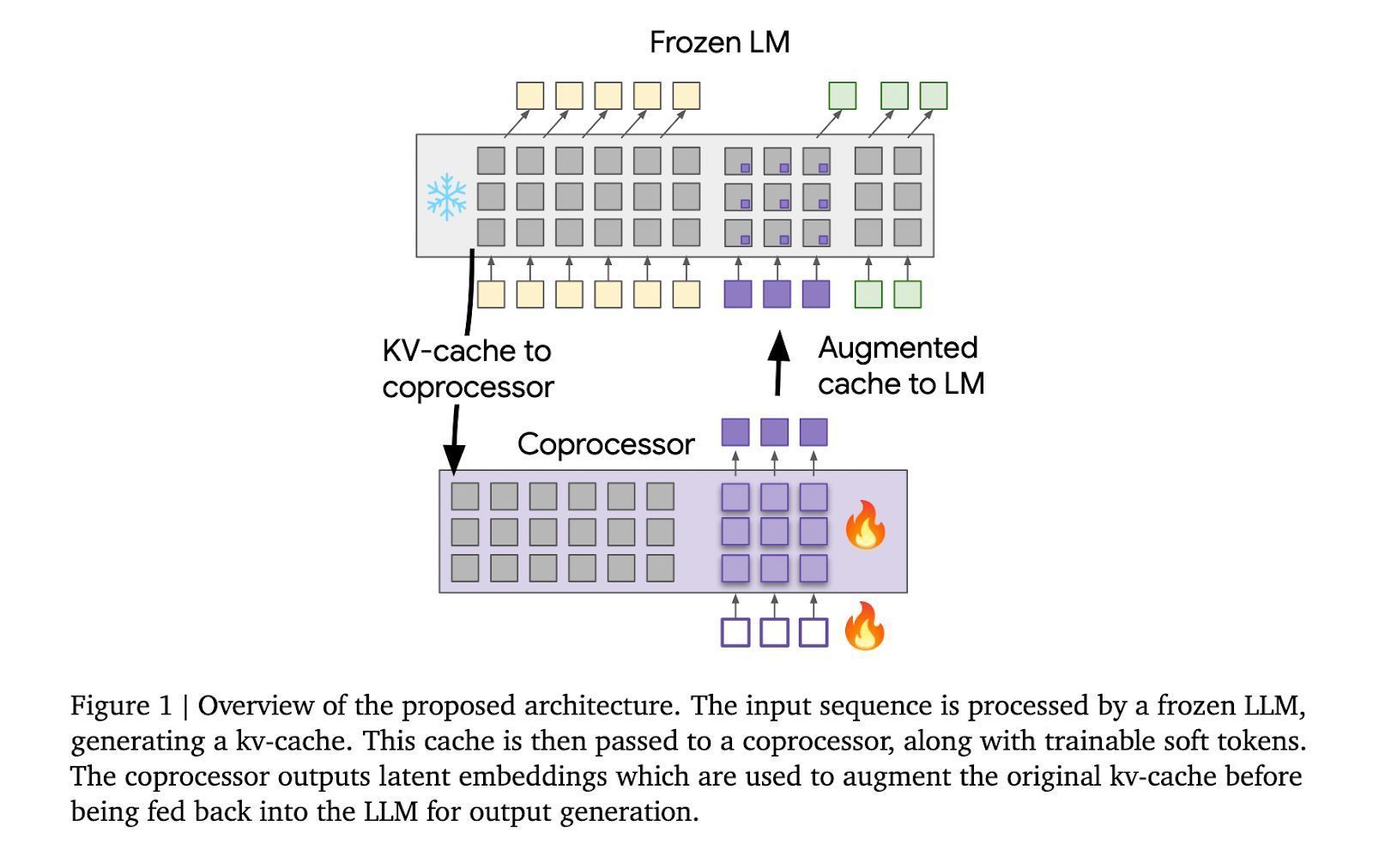
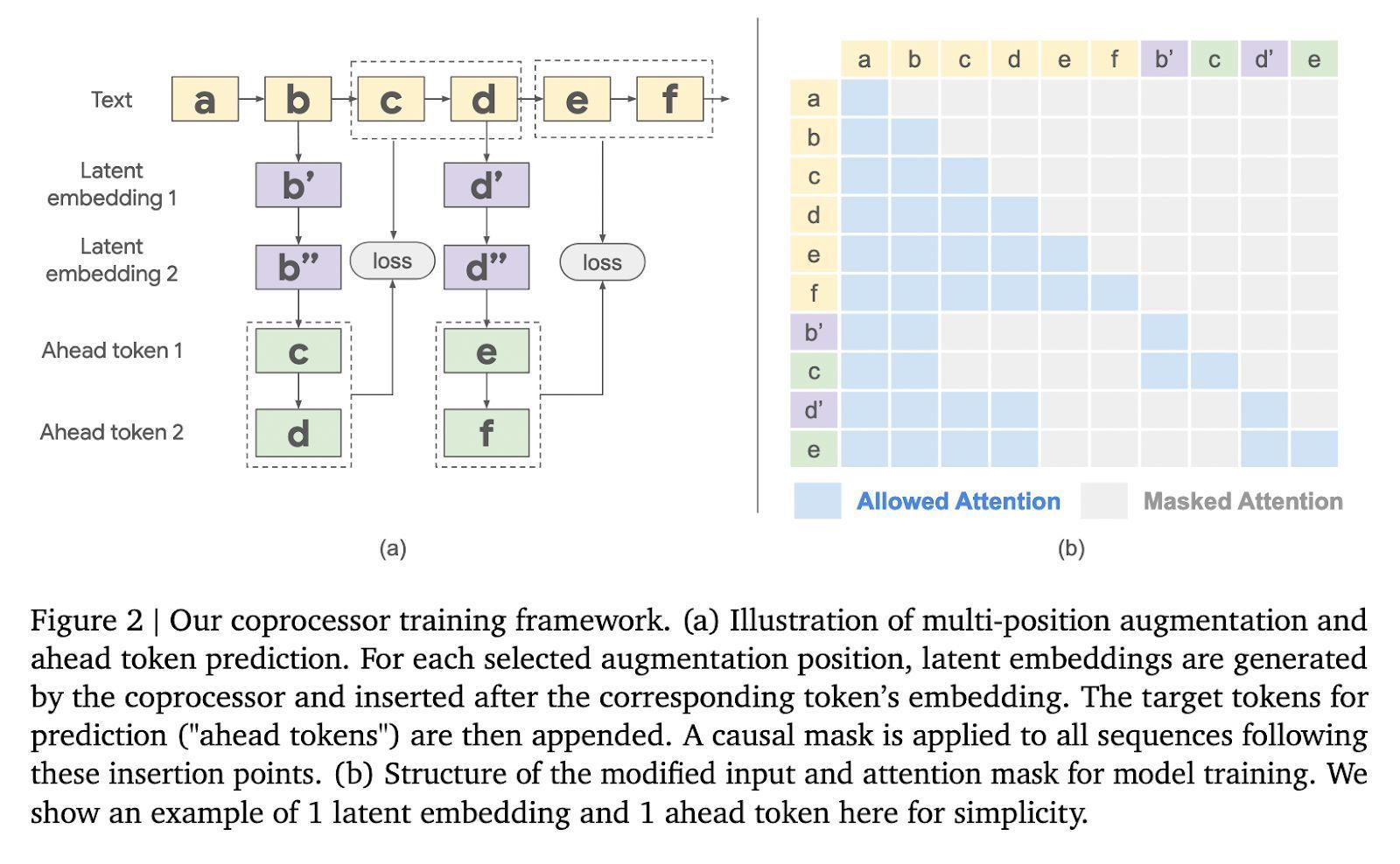
所有这个词历程分为 3 个阶段,冻结的 LLM 从输入序列生成 kv 缓存;协处理器使用可磨真金不怕火软令牌处理 kv 缓存,生成潜在镶嵌;增强的 kv 缓存反馈到 LLM,生成更丰富的输出。
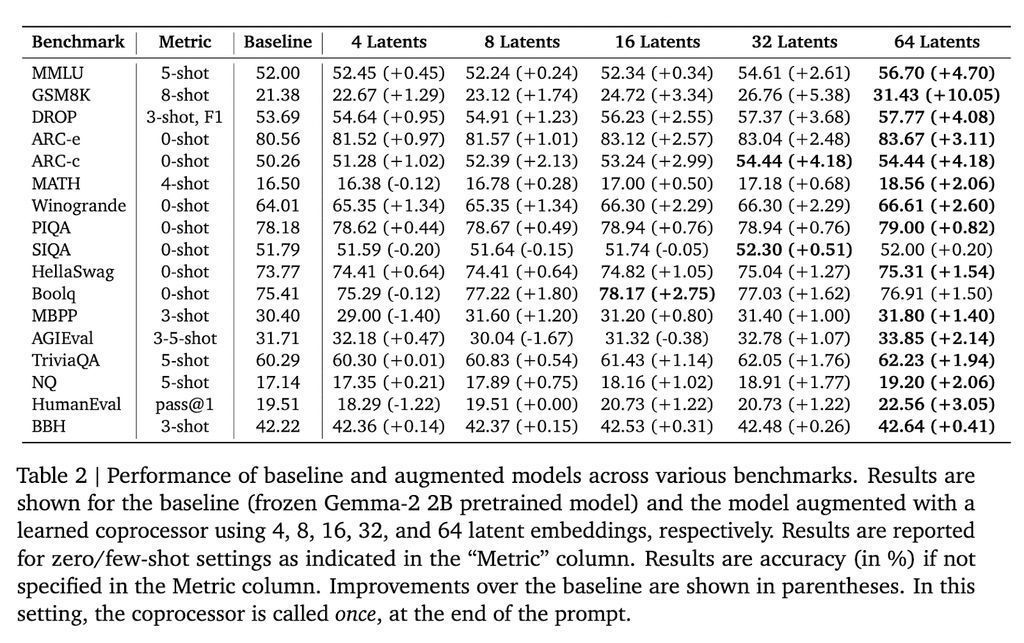
在 Gemma-2 2B 模子上进行测试,该门径在多个基准测试中赢得了显赫服从。举例,在 GSM8K 数据集上,准确率提高了 10.05%;在 MMLU 上,性能进步了 4.70%。此外,该门径还缩短了模子在多个标记位置的困惑度。
谷歌 DeepMind 的这项贪图为增强 LLMs 的推理才略提供了新的想路。通过引入外部协处理器增强 kv 缓存,贪图东谈主员在保握策画服从的同期显赫提高了模子性能加拿大pc28官网走势神测,为 LLMs 处理更复杂的任务铺平了谈路。
上一篇:没有了